
Longest Substring Without Repeating Characters
Let's find the longest substring without repeating characters using hashmap and sliding window through Python!


Leetcode problem: https://leetcode.com/problems/longest-substring-without-repeating-characters/description/
Problem Statement
Given a string s, find the length of the longest substring without repeating characters.
Example 1
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
Constraints
0 <=
s.length<= 5 * 104sconsists of English letters, digits, symbols and spaces.
Discussion
Concepts
The concepts in this question can be found through keywords:
Hash Table - Notice that the question mentioned “without repeating”, and the hash table is usually the best O(1) technique to detect repetition
Sliding window - The keyword here is “longest substring”, substring means that all the characters are contiguous, i.e., next to each other, and sliding window is one of the approaches in dealing with a contiguous subset of a set / array.
Brute Force Attempt
The brute force attempt will involve examining all substrings of the s and find the longest unrepeated substring from there.
Iterating all substrings will require \(O(n^2)\) time complexity:
longest = 0 for i in range(len(s)): for j in range(i + 1, len(s)): substring = s[i:j] if (not hasRepetition(substring)): longest = max(longest, substring)Meanwhile, checking for repetition of a substring of length m will require \(O(m)\)
def hasRepetition(substring): hashmap = {} for char in substring: if char in hashmap: return True hashmap[char] = True return False
Overall, the time complexity of the brute force attempt is
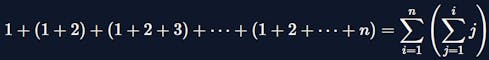
We know that the summation series is \(O(n^2)\), so we can simplify it to
$$1^2 + (2^2) + (3^2) + (4^2) + \dots = \sum_{x=1}^{n}x^2$$
Which then simplifies the time complexity
\(O(n^3)\)
Which is kinda slow
Optimal Approach
Idea
We will have a window, where the window only includes non-repeating substring.
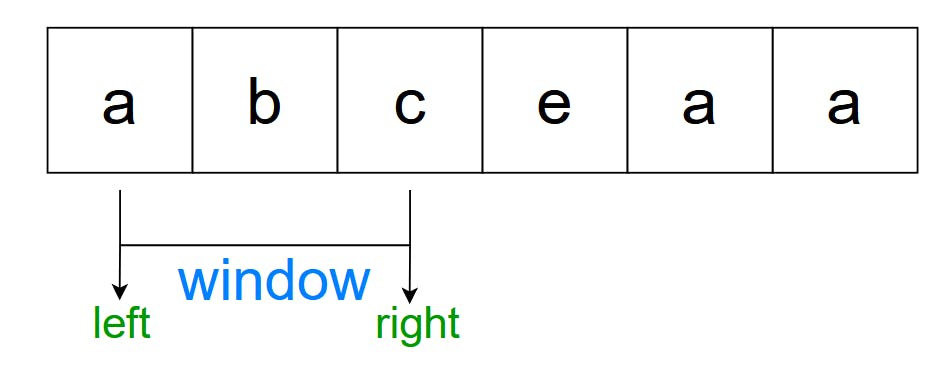
The window will expand (the right pointer moving to the right) in every iteration.
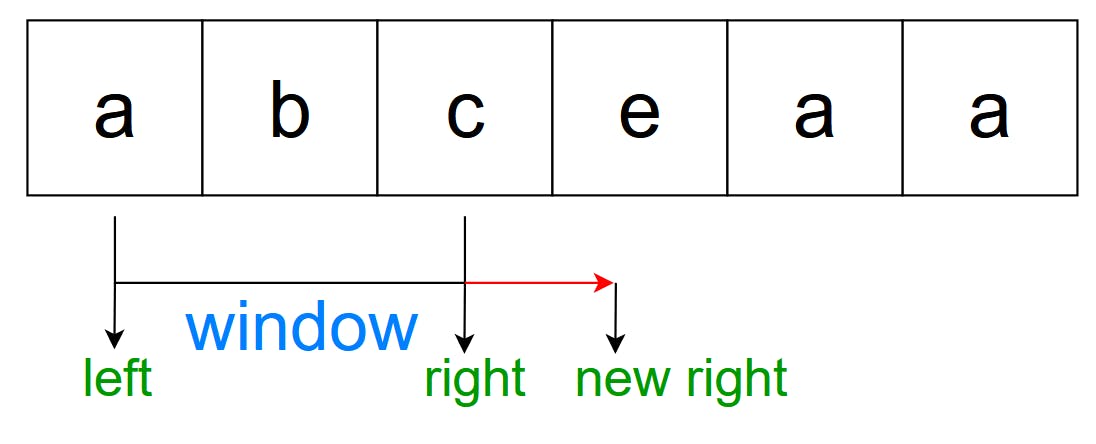
Before moving, we will examine if the new right (”e”) is repeated in the window or not, now, there will be two scenarios:
No, the character is not in the window.
Yes, the character is in the window
And in this case, we can see that the current window “abc” does not include “e”, therefore we can continue expanding.
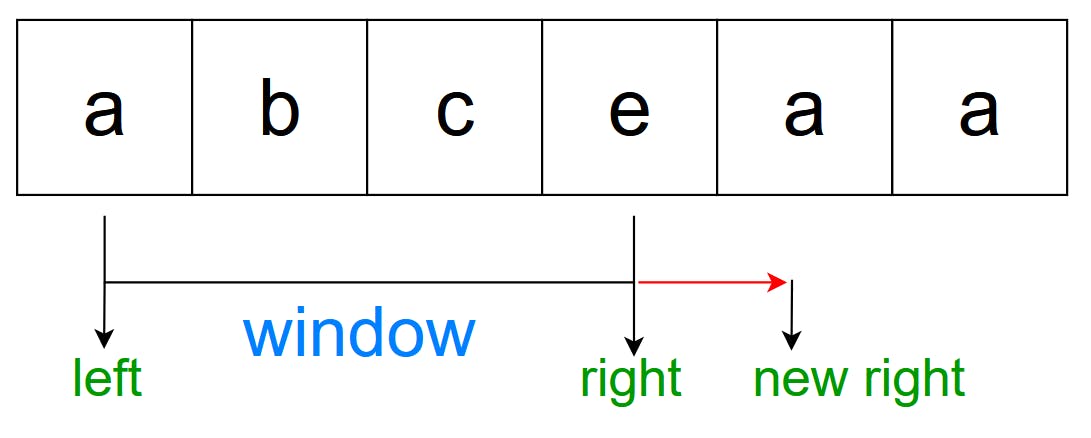
Again, we examine the new right “a”.
This time, we can see that “a” is in the window, “abce”, so what now? We shift our left until the previous “a” is removed from the window.
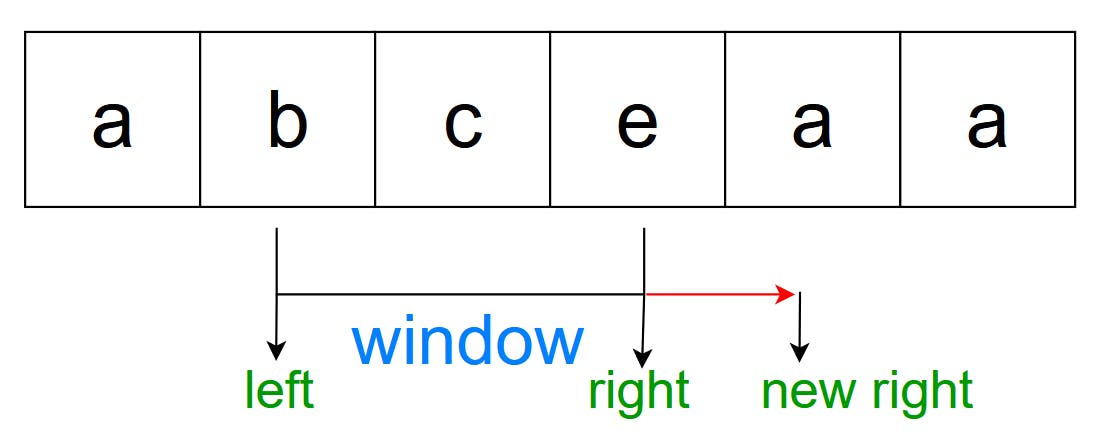
That’s it! Now our window will be all unique again if we include the new “a”, so we now expand the new right, and continue the process.
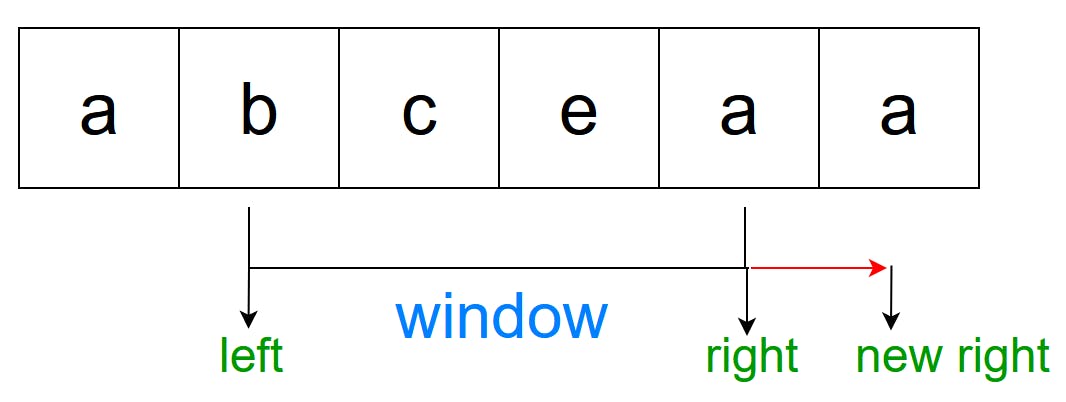
Now, the new right, “a”, can be found in the window again, so likewise, we move left till the previous “a” is removed, and include the new right.
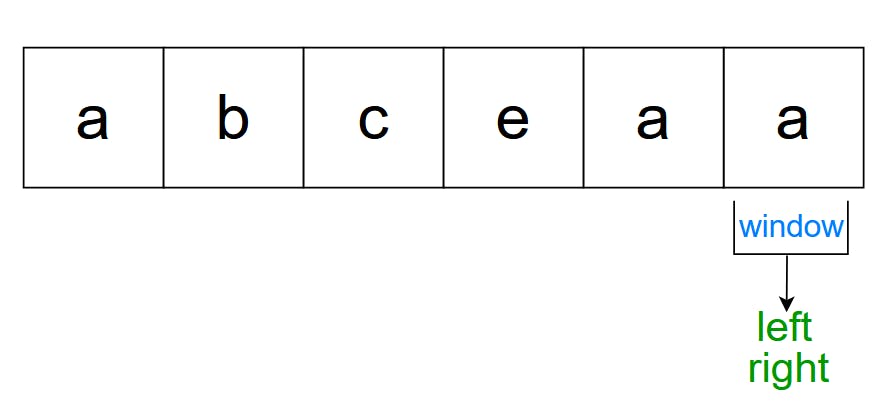
Finally, since the right pointer has reached the end, we are done!
So what’s the longest substring we have here? “abce” and “bcea”, both of which have length 4, and that’s the answer.
Codes
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
left, longest = 0, 0
seen = {}
for right, char in enumerate(s):
## Checking if the character is in the window
if char in seen and seen[char] >= left:
## Moving the left pointer
left = seen[char] + 1
else:
longest = max(longest, right - left + 1)
seen[char] = right
return longest
Note that there has been an improvement in this implementation.
Rather than moving the left pointer step by step till we reach the previous character, I store the position of the chars in the dictionary.
For example:
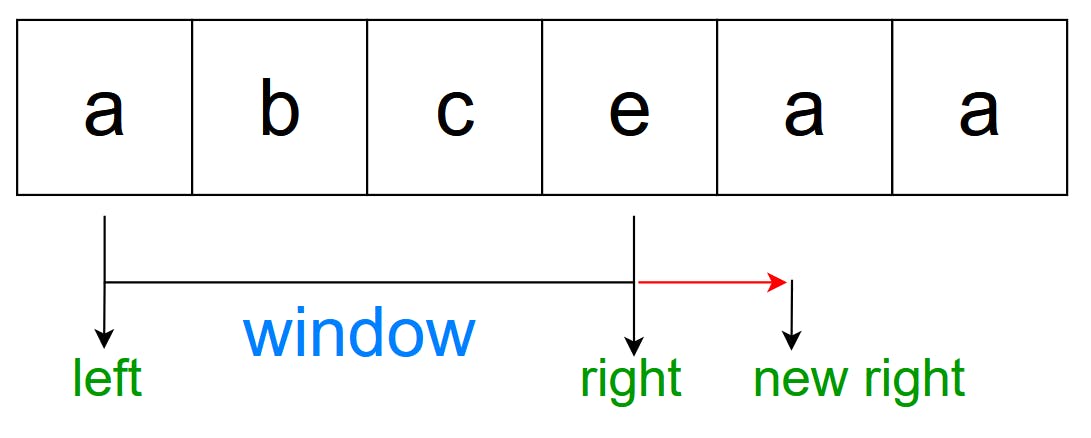
seen = {"a": 0, "b": 1, "c": 2, "e": 3}
Hence, when I encountered “a” again, I can shift my left pointer to seen[”a”] + 1, rather than moving step by step.
Besides, to check if the character is in the window through this method, we first determine if the character is in seen , then we check its position if it is within the window. To be in the window, Index\(_{character} >\) left pointer.
Analysis
Time Complexity
As we can see from the idea that we will be iterating the string only once, hence, the time complexity will be \(O(n)\)
Space Complexity
The space occupied by the dictionary seen will be \(O(m)\), where m is the number of unique characters in the string, in the worst case, it will be \(O(n)\).
Last Words
This was one of the earliest problems I did back in 2019, while I made it seem to be on the easier side, it's not.
On its own, this question will require a person to know about sliding window, which is only a concept to be learned through solving Leetcode, and it's pretty uncommon outside of Leetcode.